Hello Docker
此篇文章內容不一定都正確,若有錯誤可以跟我說。
前言
最近剛好接了lab的maintainer,身為一個初初初初學者,需先對docker有一定程度的了解,加上剛好手上有一個專案的code環境建置很麻煩,且當時疏忽沒記錄環境建置的流程,因此想記錄順便寫個腳本來建置環境,期望自己可以把server以及系統相關的內容學好。
Introduction
在使用 GitHub 上的程式碼進行開發時,常會遇到環境相容性的問題。例如 PyTorch 和 CUDA 的版本對不上,導致程式無法順利執行;又或者當你完成開發並確認程式可正常運行後,換到另一台主機執行時,必須重新安裝所有相依的套件與工具,不僅耗時費力,還容易出現錯誤。
Docker 是一種輕量級的容器技術,能夠將整個開發環境(包括作業系統、所需的套件、函式庫等)打包成一個可移植的映像檔(image)。這樣就能避免每次換環境都要重新安裝,確保專案在不同主機上也能有一致的執行結果。
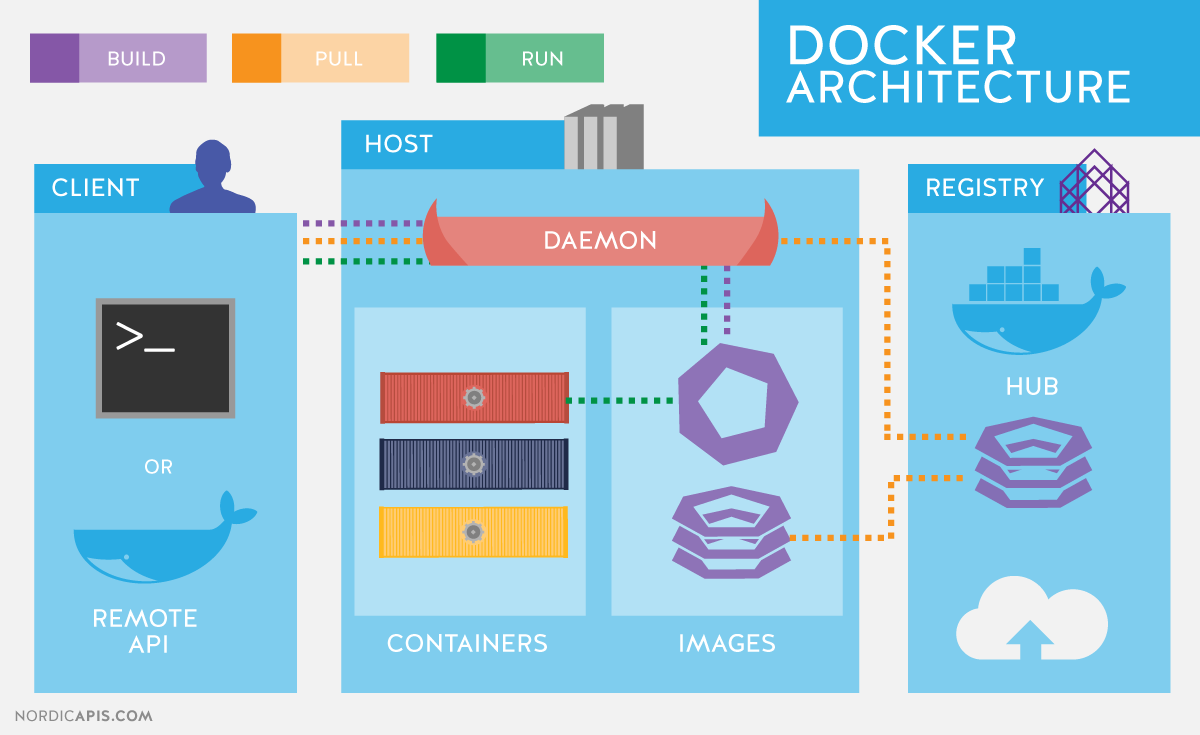
舉例來說,在撰寫深度學習相關程式時,常常需要搭配特定版本的 CUDA、cuDNN 和 PyTorch,手動安裝過程既繁瑣又容易出錯。此時可以直接從 Docker Hub 下載與需求相符的官方映像檔,再透過撰寫 Dockerfile 客製化環境,快速建構一個可重現的開發空間。
這篇文章將簡單記錄我自己使用 Docker 建置開發環境的過程,並整理常用的指令與腳本範例,整體流程包含:
- Docker相關工具安裝 & 環境建置
- Docker常用指令
- 腳本範例 & 實作流程
網路上有很多寫得很好的教學,這裡主要是就我自己的理解和實作流程做記錄,方便以後進行開發,若是以後實驗室的maintainer或是同事也可以來這裡參考 (如果你找的到的話XD)
Docker相關工具安裝 & 環境建置
基本觀念
依我目前的理解,一個系統(例如實驗室的 server)通常可以分為兩個層面:Host(主機端)與User(用戶端)。像我們在實驗室透過 SSH 登入某台 server,其實就是以用戶身份遠端連線到某個 Host,並透過給定的 IP 和 Port 進行操作。
在多使用者共用一台主機的情境下,Maintainer 通常會預先建立一個通用的 Docker Image,供多位使用者進行開發。而這裡有一個重要的問題:「為什麼同一台主機不同環境不會互相影響?」
從我個人的經驗來看,相較於使用 Anaconda 創建虛擬環境,Docker 的環境隔離性明顯更強。Anaconda 雖然可以建立不同的 Python 環境,但仍然與 Host 有一定程度的共用,例如路徑、某些共享資源等,因此還是可能遇到版本衝突、權限錯誤或是套件重複安裝的問題。
Docker 則不同。每一個 Container 是根據一個獨立的 Image 建構出來的虛擬環境,這個環境擁有自己的檔案系統、依賴項和程式碼空間。除了硬體資源(例如 GPU、CPU)共用外,Container 之間基本是互相隔離的。就算你在同一台筆電開了多個 Container,彼此也不會互相影響,這就是 Docker 最核心的設計理念之一。
工具安裝 & 環境建置
若要在自己的電腦上建container跑code,首先要先安裝docker desktop,直接去搜尋並根據你的電腦選擇不同的安裝版本,以我當時安裝的版本為例,我的電腦CPU是11th Gen Intel(R) Core(TM) i7、OS是window 64bit的,因此選擇下載window AMD 64的版本,下載後開啟執行檔即可,若要確認是否安裝成功,可以在電腦的terminal/cmd執行:
1 | docker --version |
IDE基本上一定選VScode啦,但要記得安裝Extension module,主要是Docker以及Dev Containers,這樣環境就建好了。
假設你已經建好並啟用container,要在VScode做開發,你可以在左邊 CONTAINERS 區塊中找到你正在執行的 container(或其容器 ID),右鍵點擊容器 → 選擇 Attach Shell,你就可以進入到container的bash
Note: VScode docker Extension 官方網站: https://code.visualstudio.com/docs/containers/overview
Docker desktop剛進去會要登入,這部分就看你要怎麼登,另外,進去本身會有一個welcome的container範例可以跑,跑成功會產生一個local的網址,點進去如果有顯示UI介面你就成功了。
Note: 更進階的內容涉及 Linux Namespace 與 Cgroups 等機制,有興趣可能就要去翻書了。
Docker常用指令
這裡會簡單快速記錄我實作時會用到的command,看緣分作補充,沒寫到的可以在去查,假設我使用的image是nvidia/cuda:11.1.1-cudnn8-devel-ubuntu20.04,筆電(host)有 GPU(已裝好 NVIDIA driver + CUDA + Docker GPU support),也寫了一個腳本來 build image(後面章節會細講)。
建構image (跑腳本),通常會在host端的terminal / cmd跑,若腳本沒問題,執行成功會export一個image檔案
1 | docker build -t <image name> . |
若要確認建置有沒有成功,可以在terminal輸入
1 | docker images |
他會輸出類似以下的內容:
1 | REPOSITORY TAG IMAGE ID CREATED SIZE |
成功建出image後,接著要根據這個image建構container:
1 | docker run --gpus all -it --rm <image name> /bin/bash |
–gpus all:啟用所有 GPU(需要安裝 NVIDIA Docker 支援)
-it:讓你進入容器並互動(interactive terminal)
–rm:容器關閉後自動刪除(可省略)
/bin/bash:進入 bash 終端
但這個指令會每次都要重建container,你改的東西不會保存,若不想的話就把--rm刪掉:
1 | docker run --gpus all -it --name <container name> <image name> /bin/bash |
之後要進container就可以直接key以下指令:
1 | docker start -ai <container name> |
若要查看所有啟用的container,指令是:
1 | docker ps -a |
會列出目前所有的容器(包含關掉的),你可以看到 container name、狀態、執行時間等等。
假設進入container後,你要傳輸很多檔案,例如dataset,你就要掛載資料夾(啟動容器時),這樣你把檔案放到那個資料夾,container就會自動去那個資料夾抓檔案進去,指令是:
1 | docker run --gpus all -it -v "<host的共享資料夾路徑>:<container內共享資料夾的路徑>" <image name> /bin/bash |
範例:
1 | docker run --gpus all -it \ |
Note: 如果是網路上的檔案,可以直接用wget或是curl (可能需額外載package)
🐳 Docker + 🐧 Linux 快速筆記
🔨 建構與執行
1 | docker build -t <image_name> . |
🔁 啟動 / 停止 / 進入 container
1 | docker start -ai <container_name> # 啟動並進入 |
🧹 查看 / 刪除
1 | docker ps -a # 所有容器 |
📂 Volume / 資料夾掛載
掛 host 資料夾到 container:
1 | docker run -v "<host_path>:<container_path>" <image> |
例如:
1 | docker run -it -v "/home/user/data:/workspace/data" my_image |
Note: Volume 是 Docker 用來持久化資料(保存資料)的一種方式,簡單來說會把檔案保存到host端的檔案系統,而不是container,就不會不見了
🛠 Container 內 Linux 常用指令
📁 檔案 / 路徑
1 | pwd # 查看當前路徑 |
🔧 套件管理(Ubuntu/Debian)
1 | apt update |
📊 系統狀態
1 | nvidia-smi # 查看 GPU |
腳本範例 & 實作流程
環境配置
通常這種系統層面的內容,沒有實際run過一次流程會似懂非懂,因此我也把實際例子記錄在這邊,IDE和工具的安裝前面章節已經說過就不再提,先來講我的使用情境,我在github找了一個source code來做開發,是一個叫做3detr的model。

裡面對於點雲的前置處理有用CUDA進行加速(FPS、Ball Query etc.),因此除了torch和CUDA版本要注意外,還要跑一次PointNet的編譯,我在server開發時測過可以跑的版本:
| Library | Version |
|---|---|
| PyTorch version | 1.9.0 |
| CUDA version | 11.1 |
| cuDNN version | 8.0.5 |
| CUDA Device Name | Quadro RTX 8000 |
我現在想要把建置環境的過程寫成腳本,然後產生image,這樣以後可以直接拿image來用,就不用手動key指令安裝了,測試的平台是筆電,顯卡是RTX 3060。
實作流程
🛠️ 實作流程總覽
- 撰寫
Dockerfile建立環境 (要去放置腳本的資料夾下build image) - 在
Dockerfile中安裝必要套件與依賴 - 建立 image → 執行 container
- 進 container 內 build PointNet2 CUDA 模組
- 測試是否能正常執行程式
要在放置Dockfile資料夾底下key指令,Dockfile內容如下:
1 | # 使用 NVIDIA 官方 CUDA + cuDNN image |
entrypoint.sh是為了要進入bash後自動activate虛擬環境,內容如下:
1 |
|
🧱 建立 Image
在 Dockerfile 所在資料夾,執行以下指令:
1 | docker build -t 3detr_image . |
若成功建置會輸出image檔案,可以用指令查看。
⚠️編譯PointNet那邊會出現警告和錯誤訊息,但這部分可以先忽略,不過記得要確認是否仍能 import 成功
🚀 執行 Container
掛載本機資料夾、啟用 GPU、保留 container:
1 | docker run --gpus all -it -v "...:/workspace/shared" --name 3detr_container 3detr_image /bin/bash |
若要直接啟用container(第一次是上面的指令),可以輸入以下指令:
1 | docker start -ai 3detr_container |
執行成功會直接進到container裡面,理論上一進去會直接進到3detr的虛擬環境,若沒有可執行以下兩行:
1 | source /opt/conda/etc/profile.d/conda.sh |
run起來後可以直接在VScode裡面開發,進入預設的3detr虛擬環境當中,CUDA相關套件都已經在腳本裡面建好,image也是用NV官方的,因此可以跑Python code測試CUDA和torch是否能使用。
接著要載入dataset,這邊是用SUN RGBD,詳細流程README裡面有說,大致就是要跑MATLAB code拿到SUN RGBD的data,並分成training & validation set.
然後就是下載pre-train model跑testing,官方的指令如下:
1 | python main.py --dataset_name <dataset_name> --nqueries <number of queries> --test_ckpt <path_to_checkpoint> --test_only [--enc_type masked] |
但我第一次跑會報錯,所以我直接把該專案fork過來後,將改過的code加進去變成我的Github repo:
詳細說明可以去repo看README,但我沒動model,只改了dataloader而已,以上就是大致的實作流程。
實作遇到的問題
我建好container進去時,理論上要做training的話要先extract data,要去datasets裡面個個對應的dataset的.py檔去跑,過程中可能會有路徑問題或是腳本沒安裝到的函式庫,可能要手動安裝,pip/conda都可以。
另外,我用custom data(我自己的data)training時由於我的筆電GPU記憶體不大(6GB VRAM),所以會出現以下錯誤訊息:
1 | RuntimeError: CUDA out of memory. Tried to allocate 512.00 MiB (GPU 0; 6.00 GiB total capacity; 3.67 GiB already allocated; 0 bytes free; 3.70 GiB reserved in total by PyTorch) |
我的解法是把原本的batch size降低(8 -> 2)有順利跑成功,但是若是在其他更大的dataset(如SUN RGBD)消耗的記憶體一定更多,這一點要注意,但這次只是做實驗而已。
結語
經過這個禮拜操作和實際去機房看,對於整個系統和docker的瞭解更深了,希望之後我也有能力除錯,並把server維護好,但maintainer只是協助user建container,裡面的環境還是得靠各位自己去建,我們只是協助而已,這一點要注意。
另外,若這個案子沒結掉,之後有學弟妹接到,我有盡量整合環境和code了,也有丟到github,但Custom data只能找我拿(不公開),會再找時間把多餘的檔案刪掉整理一下,希望我可以順利撐到畢業。。。

This is the author card.
Welcome to D.S., wish you a nice day .